好像很久沒有發 statistical consulting 的文章,因為這幾年在護理系什麼樣大大小小的統計問題都遇過了,後面的挑戰性就越來越低,所以也沒遇到什麼麻煩。
不過上星期一個 clinical staff 的人寫 email 給我請求統計協助。她說她找了兩個我們系上的學生問,可是他們都不會。我想說這是什麼樣的天大難題,居然讓兩個生統系博士班的學生束手無策,所以我就先答應了她,然後把她 email 給我的一個文件下載來看看。
結果,短短兩頁的說明文件,讓我看了一個多小時才看的懂。不是她寫的用字太難,而是整個敘述相當沒有條理。後來經過我額外整理出十點條目才把她的研究和問題釐清。
簡單來講,這是一個針對膝蓋手術後的療程試驗,有實驗組和對照組。實驗組用的是新療程,對照組當然是用傳統方法。但問題時,這六十幾個病人有些在進入這個臨床試驗時就已經用了額外的療法,有些病人則是在進入試驗後,自己額外去使用別的療法。總之這些病人的疼痛效應完全被跟實驗不相干的療程給干擾到了。
而基本上這種情況幾乎可以預想到統計分析的結果絕對會有偏差,而他們也不可能再用原始的組別(實驗組vs對照組)去作檢定或分析。但要他們去重新收資料已經是不可能了,畢竟金錢和人力都花下去了,現在就看有沒有辦法在 study design 上作任何改進。
當時我第一個想到的就是重新分群,但每個人有各自不同複雜的情況,即便是這位 staff 寄給我資料我還是看不太懂。今天她跑來親自解釋給我聽這些病人的狀況,我再依照她的敘述把上星期整理的十個條目減為八個條目,然後設定八個 binary 變數來代表這八個條目。最後把這八個變數丟去跑 cluster analysis 後畫出像這樣子的樹狀圖: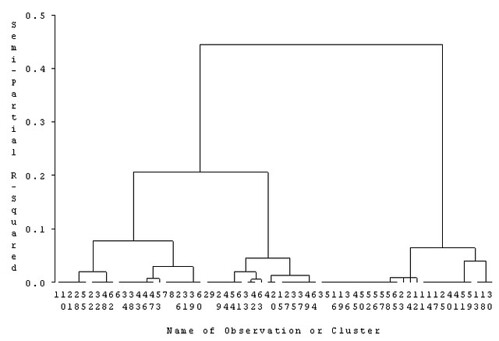
然後就叫她把 output 帶回家自己去歸類並重新替新組別命名,而這部分我就幫不上忙了,因為只有她最瞭解每個病人的特徵。我請她去朝找尋同一組人有沒有共同治療特徵,再用有意義的名稱去定義新分群。而這也是目前我想到唯一能讓她繼續把接下來的分析弄完的方法。希望老天爺夠照顧她能讓她真的找到好的新分群。


 留言列表
留言列表
